Data, Systems and HPC (DaSH) Lab
BITS Pilani K. K. Birla Goa Campus, India
Data and I/O
DaSH Lab work on various data optimization techniques like compression or prefetching on various platforms like scientific workflows or database.
I/O Uring (Ongoing)

- How can kernel I/O optimizations affect different large-scale use-cases?
- Which aspects of key value stores and databases can benefit from I/O uring optimizationsat the kernel level?
BITS Pilani Personnel: Arnav Gupta, Druva Dakshinamoorthy, Arjun Jagtap
Few Published Papers: Cluster2024
Data Compression (Completed)
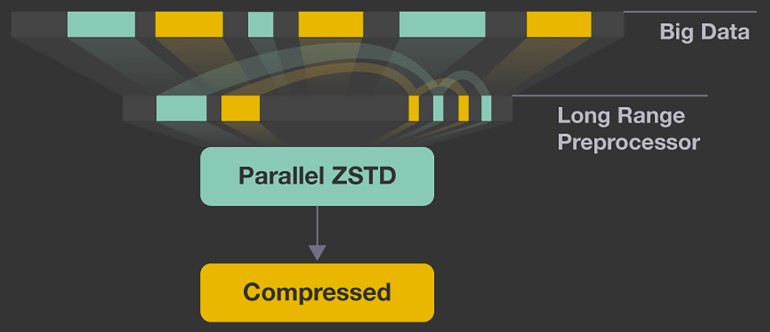
- Can we have a cost optimization model for running data compression algorithms on the cloud vs the end devices?
- How do the different optimization parameters of zstd fare against each other?
- How do large VM images fare with various levels of zstd?
Collaborators: Druva Inc.
BITS Pilani Personnel: Pinki Yadav, Vinayak Naik
DataSpaces (Completed)
- DataSpaces is a data management framework for scientific workflows.
- Can optimizations be done for integrating HPC file systems into dataspaces?
- How can I/O intensive tasks be optimized in such a workflow?
Collaborators: University of Utah - USA
BITS Pilani Personnel: Joel Tony
Other Personnel: Manish Parashar
Systems for ML
DaSH Lab tries to optimize systems and build frameworks for machine learning (ML) workloads. We aim at both large-scale ML workloads as well as tiny ML workloads suitable for resource-constrained edge devices.
Privacy-aware FL (Ongoing)
- How can we adaptively tune parameters for different privacy-preserving methods in FL?
- How does privacy preserving techniques get impacted by heterogeneity in the FL clusters?
BITS Pilani Personnel: Adithya Balasubramanian, Nischit Kumar, Aishwarya Jayashankar
Multimodal FL (Ongoing)
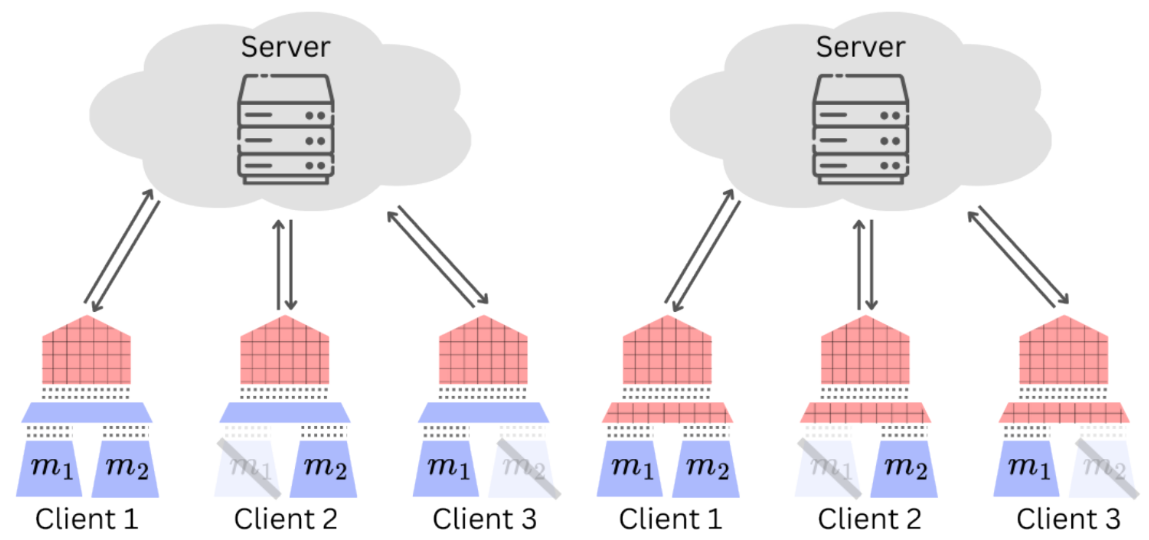
- How can we aggregate FL clusters holding different modes of data?
- How can FL aggregation handle missing modalities?
Collaborators: Queen Mary University of London - UK
BITS Pilani Personnel: Pranav M R, Jayant Chandwani
Other Personnel: Ahmed Sayed
FL for Autonomous Vehicles (Ongoing)
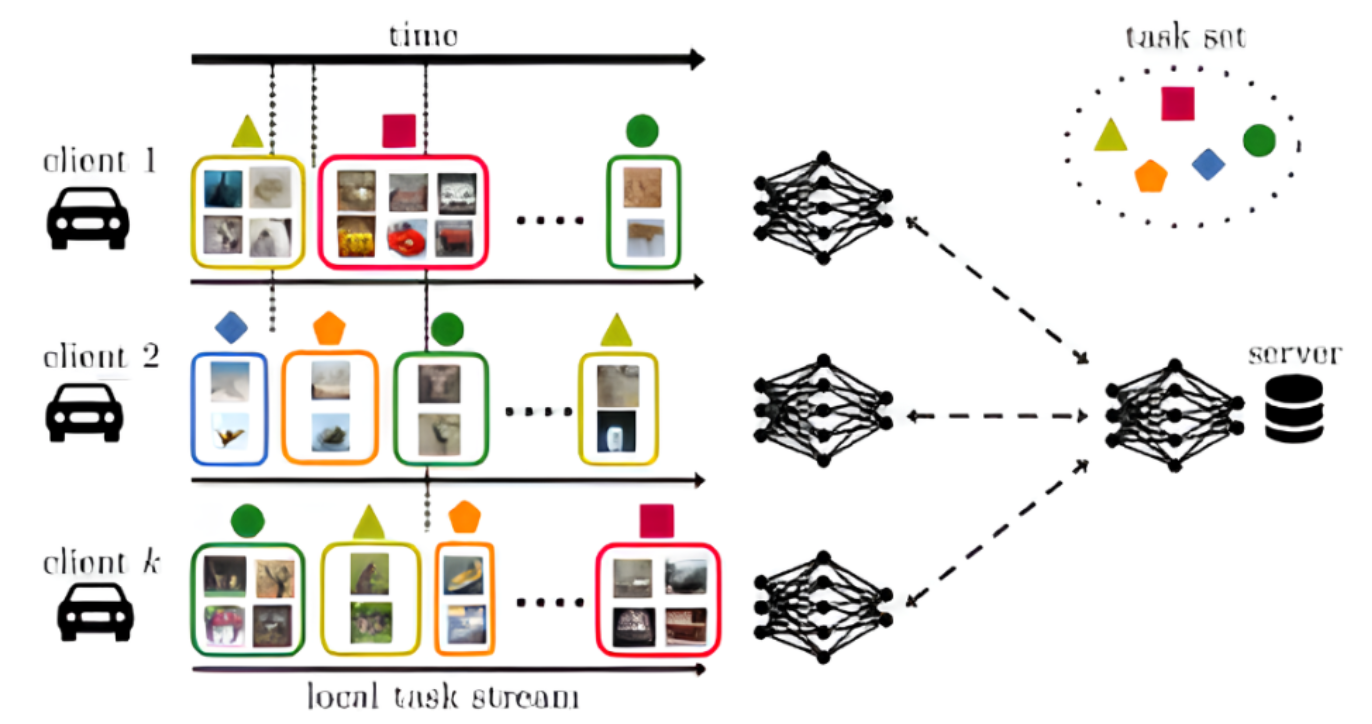
- How can FL be used for vehicles with streaming data?
- How the FL techniques adapt to the changing networking environment of vehicles?
BITS Pilani Personnel: Vimarsh Shah, Harsh Chothani, Marichamy Kasi
Few Published Papers: HiPC’25 Poster
Proof of Training in FL (Ongoing)
- How can clusters verify that clients actually do the training?
- How can cross-silo FL get validation that all participating clusters are training well?
BITS Pilani Personnel: Ojas Marathe, Surya Datta, Abhishek Kumar
Operation Pipeline in FL (Ongoing)
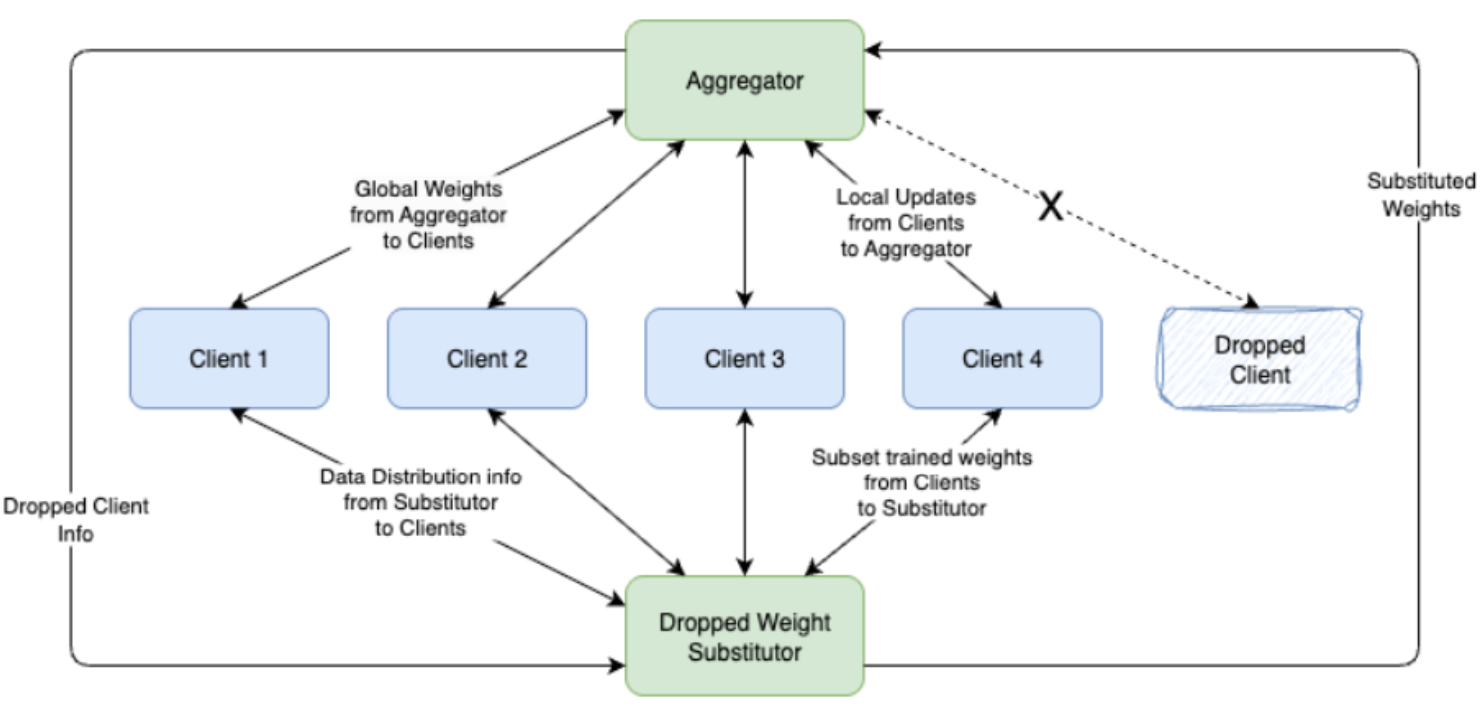
- How to integrate automation of fault tolerance in MLOps pipeline?
- Can optimizations be done for deploying FL workloads using FLOps?
- Can intelligent Infrastructure-As-Code (IAC) be deployed for MLOps?
Collaborators: Queen Mary University of London - UK
BITS Pilani Personnel: Vimarsh Shah, Aryan Bethmangalkar, Sarang S, Harsh Chothani, Aishwarya Jayashankar, Ayush Bharadwaj
Other Personnel: Ahmed Sayed
Few Published Papers: HiPC 2024 Poster, ICDCS 2025 Workshop
Scheduling LLM Inference Tasks (Ongoing)
- How can you design a scheduler that is resource-aware for a heterogeneous cluster of GPUs while scheduling LLM inference jobs?
- Furthermore, can you make the scheduler network-aware?
BITS Pilani Personnel: Aditya Shiva Sharma, Atharva Pandit
Small Language Models on Edge Devices (Ongoing)
- How can SLMs be resource-aware on edge devices?
- Can the SLM tasks be be application aware on mobile devices?
BITS Pilani Personnel: Soham Dambalkar, Utkarsh Sharma, Kunal Mishra
Cross-Silo FL (Completed)
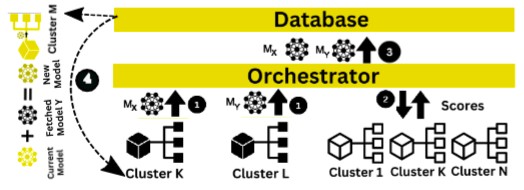
- How can multiple organizations collabate in a data-privacy manner in FL?
- Can knowledge distillation process be improved in FL?
- Are all edge devices needed to participate in a FL training process?
- Can we optimize energy in an FL process?
Collaborators: Queen Mary University of London - UK, Rochester Institute of Technology- USA
BITS Pilani Personnel: Sarang S, Druva Dhakshinamoorthy, Yuvraj Singh Bhadauria, Arihant Bansal, Pinki Yadav, Aditya Shiva Sharma, Sidharth C. Vivek, Vijay Dharmaji, Subroto Majumder, Manit Tanwar
Other Personnel: Ahmed Sayed, M. Mustafa Rafique
Few Published Papers: Middleware 2025, Poster@HiPC23
Data Caching in TinyML (Completed)
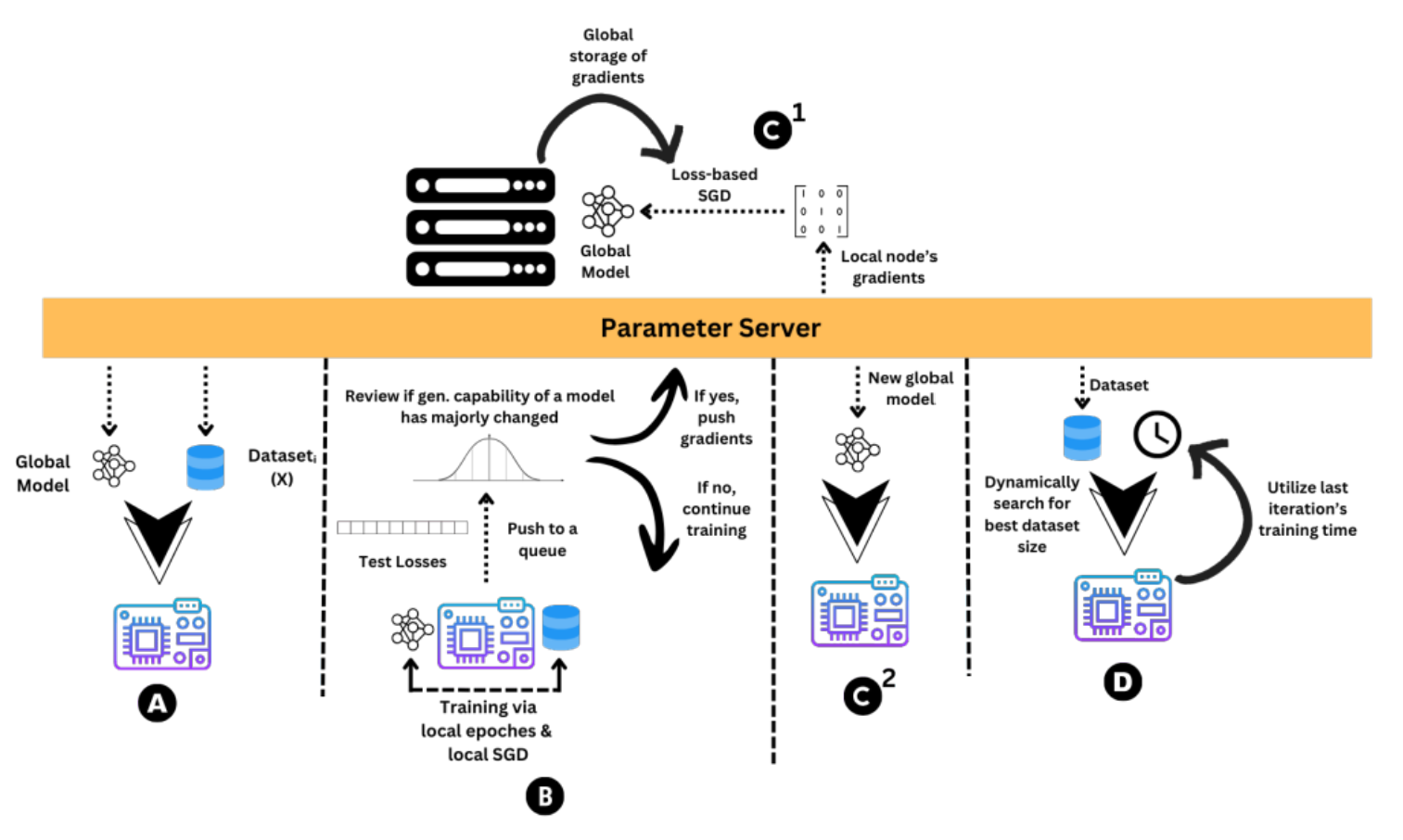
- How can distributed tinyML training be made aware of the heterogeneous edge environment?
- Can the datasets used for tinyML training be cached given the low resources on the devices?
BITS Pilani Personnel: Advik Raj, Sidharth C. Vivek, Advaith Krishna
Few Published Papers: HiPC'24
Distributed Systems
DaSH Lab works on emerging areas of distributed systems, such as, serverless compute, blockchain, and cloud computing. All projects use state-of-the-art technologies like Kafka, Ethereum, Kubernetes, Docker.
Trust in Serverless
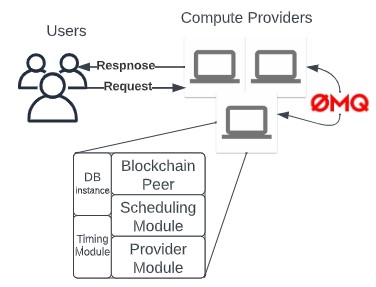
- How do you form a framework for FaaS using personal devices?
- How do you enable trust among the geo-distributed personal devices?
- How does one schedule FaaS on these devices?
- How is the cost of running FaaS provider services calculated?
BITS Pilani Personnel: Aalhad Sawane, Pranav Anand, Satyam Bansal, Pranay Varshney, Paras Mittal, Chinmay Rao, Amogh Balepur
Few Published Papers: Poster@HiPC23 (Best Undergraduate Poster Award)
Cross Cloud Compatibility
- How do you overcome a vendor locking situation with regards to public cloud providers?
- Can we have a middleware to have cross compatibility among major cloud providers, such as AWS, Azure and GCP?
Blockchain Smart Contracts
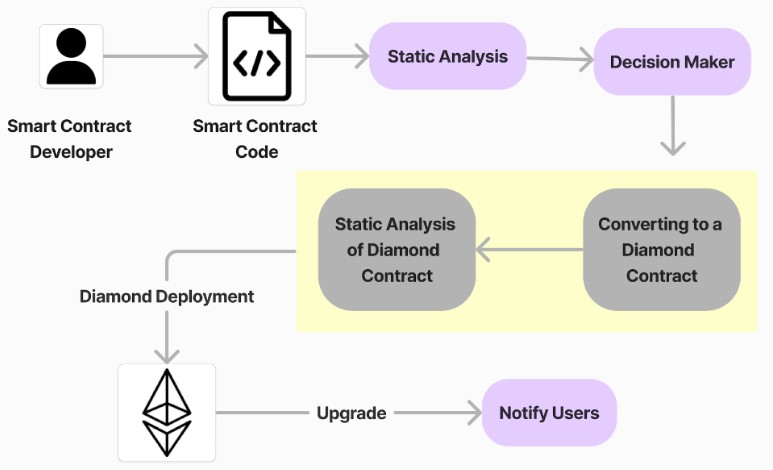
- How does one remove bugs in smart contracts after deployment?
- Are the upgrade mechanisms given by Ethereum usable for all smart contracts?
- Which upgrade patterns are most popular and why?
BITS Pilani Personnel: Aishwarya Parab, Nirmal Govindaraj, Siddhant Kulkarni, Pranay Varshney, Kunal Korgaonkar
Few Published Papers: Poster@HiPC23
Container deduplication
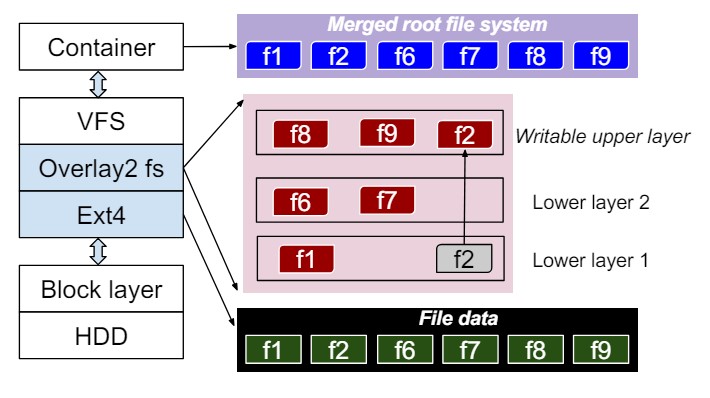
- What are the common layers in containers?
- Can common layers be deduplicated in large clusters using large amounts of containers?
- How can deduplication be solved in edge clusters with low resources?
- Can we devise caching methods for caching updates in edge clusters?
Collaborators: Virginia Tech - USA, Northwestern Polytechnical University - China, Kuwait University, IBM Research - USA, University of Minnesota - USA
BITS Pilani Personnel: Naman Agarwal, Prithvi Vishak, Nakul Bhachawat
Other Personnel: Hadeel Albahar, Nannan Zhao, Ali Anwar
Few Published Papers: ACM TOS24, TPDS20
High Performance Computing (HPC)
DaSH Lab works on the data and file system aspect of HPC. Most emerging HPC applications have complicated I/O patterns which result in sub-optimal application performance.
Parallel File System
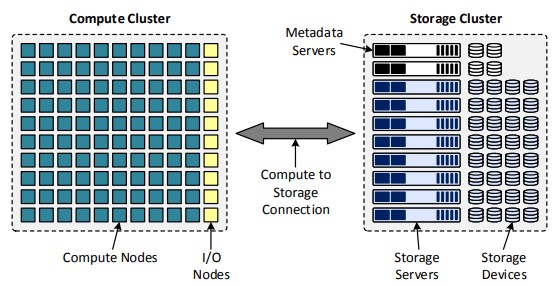
- How do you load balance I/O on to storage servers in a seamless manner?
- What is an optimal striping layout for a file within an application?
- Where to place files in a heterogeneous storage setup?
- How does network and I/O interact with each other in a parallel file system?
- How does I/O performance differ in parallel file system and object stores?
Collaborators: Virginia Tech - USA, Johannes Gutenberg University Mainz - Germany
BITS Pilani Personnel: Joel Tony, Yash Bhisikar, Bhavya Bajaj, Kaaviya Uthirapandian, Arnav Borkar, Hari Vamsi, Tushar Barman, Sreenath M.
Other Personnel: Debasmita Biswas, Sarah Neuwirth
PFS investigated: Lustre, IBM Spectrum Scale, BeeGFS, Ceph
Few Published Papers: ACM TOS 2024, Cluster 2023 (1), Cluster 2023 (2), INDIS@SC21, Cluster19, IPDPS19
Data Caching
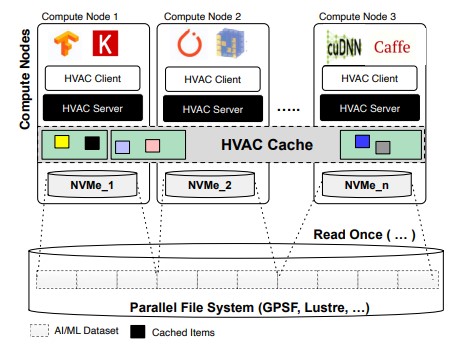
- How to remove I/O bottleneck for large-scale deep learning applications?
- How can we use importance sampling for Distributed DL applications?
- Can I/O bottleneck be reduced for HPC applications by data prefetching?
Collaborators: Oak Ridge National Laboratory - USA, University of Viginia - USA, Virginia Tech - USA, Georgia State University
Other Personnel: Ahmad Maroof Karimi , Redwan Khan, Yue Cheng, Jong Choi, Lipeng Wan
Few Published Papers: FAST23, Cluster22
Resource Scheduling
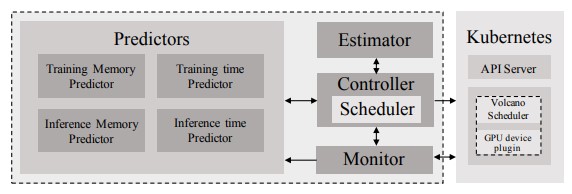
- How can distributed deep learning jobs be made GPU heterogenity aware?
- How can distributed inferencing jobs be made GPU Heterogeneity aware?
- How can containers be used in HPC environments?
Collaborators: Virginia Tech - USA, Purdue University - USA, IIT Indore, Kuwait University, Northwestern Polytechnical University - China
BITS Pilani Personnel: Aditya Shiva Sharma, Kinshuk Goel, Amey Patil, Mukul Krishnan
Other Personnel: James Davis, Siddharth Sharma, Hadeel Albahar, Nannan Zhao
Few Published Papers: CCGrid22, Cloud20
Supercomputer Log Analysis
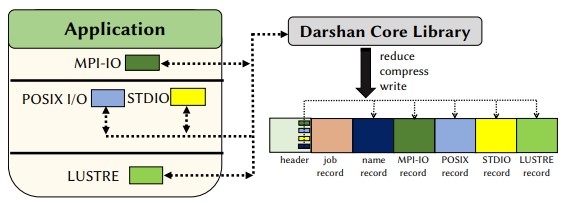
- How can darshan I/O characterization logs be used to characterize ML workloads?
- How can darshan logs be used for HPC trace generation?
- How are different supercomputing stacks used by varying HPC workloads?
- How do DL workloads differ in academia, industry and national labortories?
Collaborators: Virginia Tech - USA, Oak Ridge National Laboratory, Argonne National Laboratory, Lawrence Berkeley Laboratory
BITS Pilani Personnel: Natasha Meena Joseph, S Sai Vineet, Kunal Korgaonkar, Snehanshu Saha
Other Personnel: Ahmad Yazdani,Ahmad Maroof Karimi, Jong Choi, Phil Carns, Bing Xie, Suren Byna, Feiyi Wang, Jean Luca Bez
Few Published Papers: ICDCN23, MASCOTS21, HPDC22, HPDC22